前言
- redis在项目中是经常会使用的一种缓存数据库,了解其一些配置和设计思路有利于我们更有效安全的使用它
- 这次分析一下Redis的主从架构机制,所谓知其然知其所以然。
搭建过程
- 想要了解Redis的主从架构机制,最好的办法是自己搭建一套Redis主从架构。
- 下面我们搭建一个redis一主二从的主从架构。
- 首先下载一个单机redis服务器,然后复制两份 redis-6380.conf和redis-6381.conf文件,分别更改以下相关配置从节点:
port 6380 # 从节点6380 (下同)
replicaof 192.168.0.60 6379 # 配置从节点访问主节点(下同)
slave-read-only yes # 配置从节点只读操作(下同)
port 6381
replicaof 192.168.0.60 6379
slave-read-only yes
- 在控制台执行 redis‐server redis-6379.conf、redis‐server redis-6380.conf、redis‐server redis-6381.conf。命令启动redis一主二从服务。
- 启动成功后,测试一下在主节点添加数据,从节点是否会同步主节点数据。

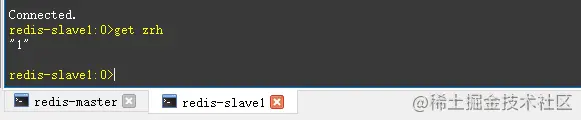
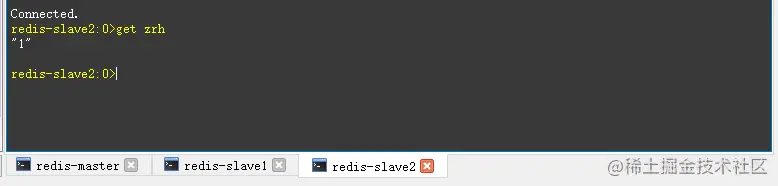
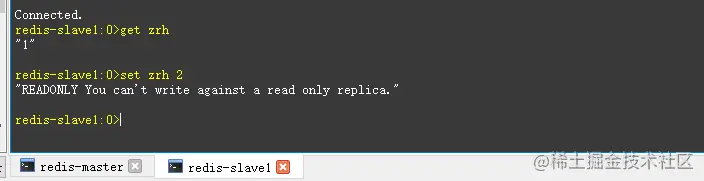
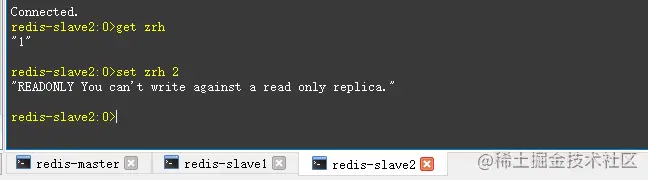
- 看上图,往主节点set数据后,在从节点能get到数据。往从节点set数据会提示read only。
分析主从一致原理
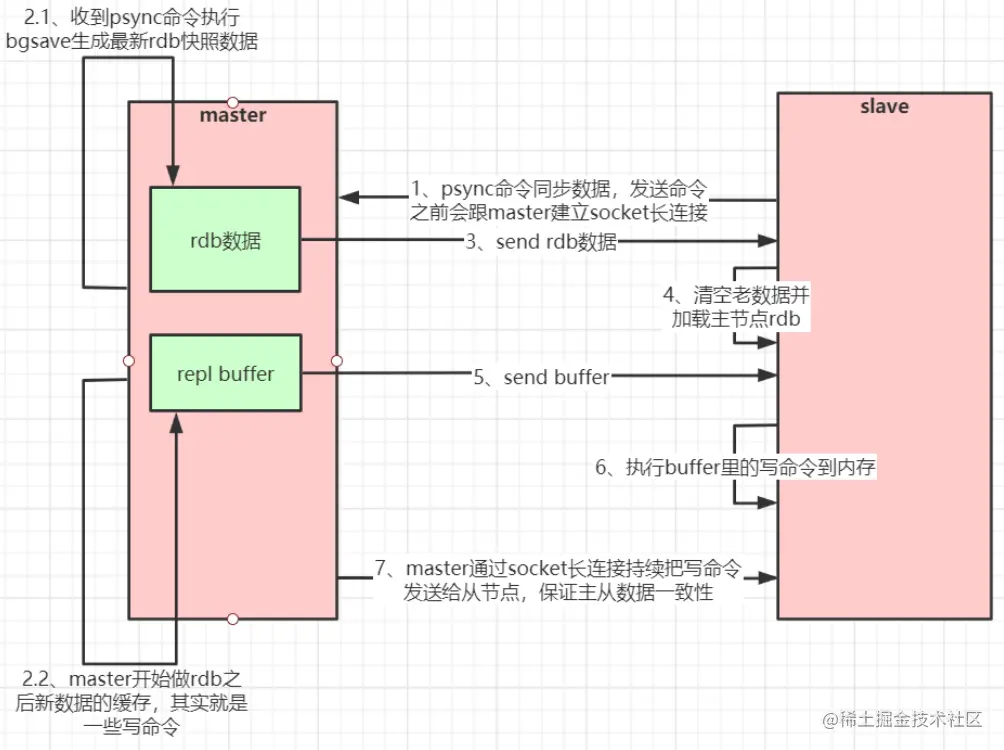
- 当我们为master节点配置了一个slave节点,不管slave是否是第一次链接上master,它都会发送一个psync命令给master请求复制数据。
- master收到psync命令后,会在后台进行数据持久化通过bgsave生成最近的rdb快照文件,期间Redis会继续接收其它客户端的请求,并把这些新的数据集请求缓存在内存中。当持久化完成后,master会把这份rdb文件发送给slave,slave会把接收到的数据进行持久化生成RDB文件并加载到内存,然后master再将之前缓存在内存中最新的数据发送给slave。
- 当slave与master再次断开链接后,slave能自动重连master,如果master收到了多个slave并发连接请求,那它也只会持久化一次,而不是一个连接持久化一次,再把这个持久化文件发送给其他slave。
Redis的master和slave第一次数据全量复制:
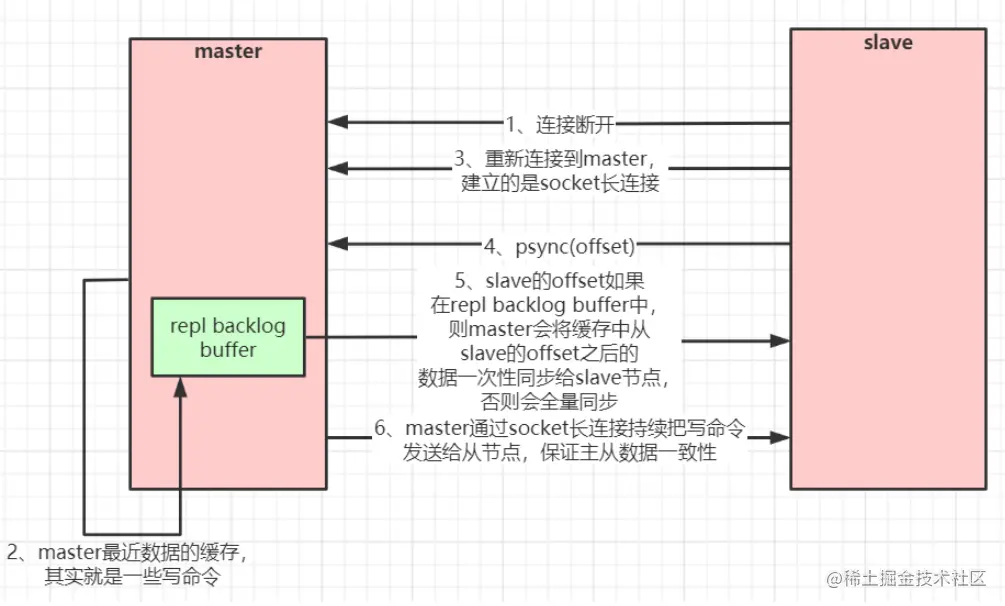
再次链接的增量复制:
- 当master和slave断开重连后,一般会全量复制数据。当在Redis 2.8版本后,redis支持增量复制数据到slave。
- master会在内存创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master进程ID。所以当slave断开连接后,slave会发送命令到master请求进行未完成的复制,从记录的数据下标开始。当master的进程ID或从节点数据下标太旧,都不在master的缓存队列里了,那么就会进行一次数据的全量复制。
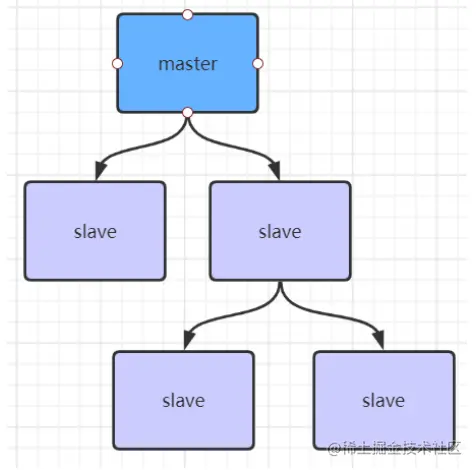
- 如果有很多slave,那为了缓解主从复制风暴(多个slave同时复制master数据,导致master压力过大),可以做下列架构,让部分slave与slave进行同步数据
来源:https://juejin.cn/post/6989967894847340552



评论区