


1.消息发送流程
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了
两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。
main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。
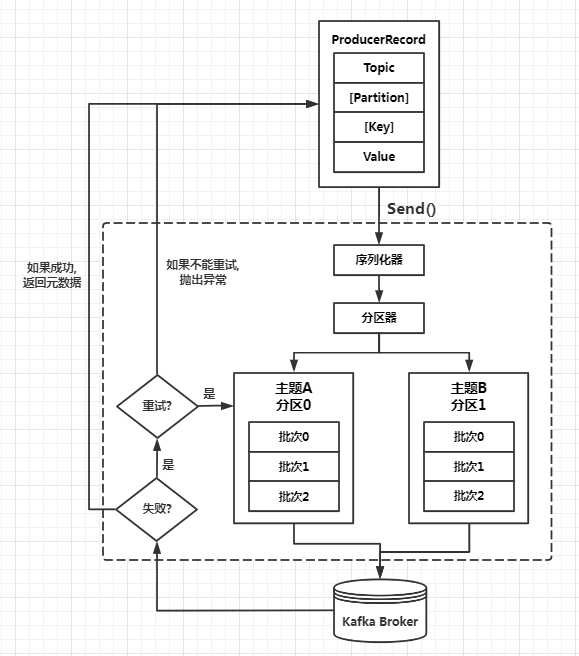
- 1.新建ProducerRecord对象,包含目标主题和要发送的内容。也可以指定键或分区
- 2.发送ProducerRecord对象时,生产者要把键和值对象序列化成字节数组,这样它们才能在网络上传输
- 3.数据被传给分区器。
- 如果ProducerRecord对象中指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。
- 如果没有指定分区,那么分区器会根据ProducerRecord对象的键来选择一个分区。
- 选择好分区后,生产者就知道该往哪个主题和分区发送这条记录了。
- 4.这条记录被添加到一个记录批次里,这个批次里的所有消息会被发送到相同的主题和分区上。
- 有一个独立的线程负责把这些记录批次发送到相应的broker上。
- 5.服务器在收到这些消息时会返回一个相应。
- 如果消息成功写入kafka,就返回一个RecordMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。
- 如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
2.生产者的配置说明
- 1.acks
- acks参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。这个参数消息丢失的可能性有重要影响。
- 如果acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应。如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
- 如果acks=1,只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达首领节点(比如首领节点崩溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。这个时候的吞吐量取决于使用的是同步发送还是异步发送。如果发送客户端等待服务器的相应,显然会增加延迟。如果客户端是使用异步回调,延迟问题就可以得到缓解,不过吞吐量还是会受发送中消息数量的限制(比如,生产者在收到服务器响应之前可以发送多少个消息)
- 如果acks=all,只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过,它的延迟会更高,因为需要等待不止一个服务器节点接收消息。
- 2.buffer.memory
- 该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send()方法调用要么被阻塞,要么抛出异常,取决于如何设置max.block.ms参数,此参数设置抛出异常之前可以阻塞的一段时间
- 3.compression.type
- 默认情况下,消息发送时不会被压缩。该参数可以设置为snappy、gzip或lz4,它指定了消息被发送给broker之前使用哪一种压缩算法进行压缩。snappy压缩算法由Google发明,它占用较少的CPU,却能提供较好的性能和相当可观的压缩比,如果比较关注性能和网络带宽,可以使用这种算法。gzip压缩算法一般会占用较多的CPU,但会提供更高的压缩比,如果网络带宽有限,可以使用这种算法。
- 使用压缩可以降低网络传输开销和存储开销,这也是kafka的瓶颈所在。
- 4.retries
- 生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领)。这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms,不过可以通过retry.backoff.ms参数来改变这个时间间隔。
- 5.batch.size
- 当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次被填满,批次里的所有消息会被发送出去。不过生产者并不一定都会等到批次被填满才发送,半满的批次,甚至只包含一个消息的批次也有可能被发送。所以就算把批次大小设置的很大,也不会造成延迟,只是会占用更多的内存而已。但如果设置的很小,生产者会更频繁的发送消息,会增加一些额外的开销。
- 6.linger.ms
- 该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或linger.ms达到上限时把批次发送出去。默认情况下,只要有可用的线程,就算批次里只有一个消息,生产者也会把消息发送出去。把此值设置成比0大的数,让生产者在发送批次之前等待一会,使更多的消息加入这个批次。虽然这样会增加延迟,但也会提升吞吐量。
- 7.client.id
- 可以是任意的字符串,服务器会用它来识别消息的来源,还可以用在日志和配额指标里。
- 8.max.in.flight.requests.per.connection
- 该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为1可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
- 9.request.timeout.ms
- 指定了生产者在发送数据时等待服务器返回响应的时间
- 10.metadata.fetch.timeout.ms
- 指定了生产者在获取元数据时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误。
- 11.timeout.ms
- 指定了broker等待同步副本返回消息确认的时间,与asks的配置相匹配--如果在指定时间内没有收到同步副本的确认,那么broker就会返回一个错误。
- 12.max.block.ms
- 指定了在调用send()方法或使用partitionsFor()方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到此值时,生产者会抛出超时异常。
- 13.max.request.size
- 用于设置生产者发送的请求大小。可以指能发送的单个消息的最大值,也可以指单个请求里所有消息总的大小。
- broker对可接收的消息最大值也有自己的限制,message.max.bytes,两边的配置最好可以匹配,避免生产者发送的消息被broker拒绝
- 14.receive.buffer.bytes和send.buffer.bytes
- 分别指定了TCP socket接收和发送数据包的缓冲区大小。如果被设置为-1,就是用操作系统默认值。如果生产者或消费者与broker处于不同的数据中细腻,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
顺序保证
- kafka可以保证同一个分区里的消息是有序的。生产者按照一定的顺序发送消息,broker就会按照这个顺序把它们写入分区,消费者也会按照同样的顺序读取它们。
- 如果应用场景要求消息是有序的,可以把max.in.flight.requests.per.connection设为1,这样在生产者尝试发送第一批消息时,就不会有其它的消息发送给broker。不过这样会严重影响生产者的吞吐量,所以只有在对消息的顺序有严格要求的情况下才能这么做。
3.发送消息的三种方式
- 导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.5.0</version>
</dependency>
- 1.发送并忘记(fire-and-forget)
- 把消息发送给服务器,但并不关心它是否正常到达。
- 2.同步发送
- 使用send()方法发送消息,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
- 3.异步发送
- 调用send()方法,并指定一个回调函数,服务器在返回响应时调用该函数
private static Properties props = new Properties();
static {
//指定kafka server的地址,集群配多个,中间,逗号隔开
props.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
//procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
//acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
//acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
//acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
//可以设置的值为:all, -1, 0, 1
props.put("acks", "all");
//写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
//当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
props.put("retries", 1);
//每次批量发送消息的数量,produce积累到一定数据,一次发送
props.put("batch.size", 16384);
//等待时间
props.put("linger.ms", 1);
//produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
props.put("buffer.memory", 33554432);
//指定消息key和消息体的序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
}
public static void main(String[] args) {
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
simpleSend(producer, new ProducerRecord<String, String>("test-topic",
Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
/**
* 最简单的方式发送,不管消息是否正常到达
*
* @param producer
*/
private static void simpleSend(Producer<String, String> producer, ProducerRecord<String, String> record) {
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 同步发送
*
* @param producer
* @param record
*/
public static void sync(Producer<String, String> producer, ProducerRecord<String, String> record) {
try {
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println("topic:" + recordMetadata.topic());
System.out.println("partition:" + recordMetadata.partition());
System.out.println("offset:" + recordMetadata.offset());
System.out.println("metaData:" + recordMetadata.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 异步发送
*
* @param producer
* @param record
*/
public static void aync(Producer<String, String> producer, ProducerRecord<String, String> record) {
try {
producer.send(record, new DemonProducerCallback());
while (true) {
Thread.sleep(5 * 1000);
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 回调实现
**/
private static class DemonProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (null != e) {
e.printStackTrace();
} else {
System.out.println("topic:" + recordMetadata.topic());
System.out.println("partition:" + recordMetadata.partition());
System.out.println("offset:" + recordMetadata.offset());
System.out.println("metaData:" + recordMetadata.toString());
}
}
}
4.拦截器
拦截器原理
- Producer 拦截器(interceptor)是在 Kafka 0.10 版本被引入的,主要用于实现clients 端的定制化控制逻辑。
- 对于 producer 而言,interceptor 使得用户在消息发送前以及 producer 回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer 允许用户指定多个 interceptor 按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor 的实现接口是 org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
- (1)configure(configs)
- 获取配置信息和初始化数据时调用。
- (2)onSend(ProducerRecord):
- 该方法封装进 KafkaProducer.send 方法中,即它运行在用户主线程中。Producer 确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区,否则会影响目标分区的计算。
- (3)onAcknowledgement(RecordMetadata, Exception):
- 该方法会在消息从 RecordAccumulator 成功发送到 Kafka Broker 之后,或者在发送过程中失败时调用。并且通常都是在 producer 回调逻辑触发之前。onAcknowledgement 运行在producer 的 IO 线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢 producer 的消息发送效率。
- (4)close:
- 关闭 interceptor,主要用于执行一些资源清理工作
- 如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个 interceptor,则 producer将按照指定顺序调用它们,并仅仅是捕获每个 interceptor 可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
- (1)configure(configs)
拦截器案例
- 实现拦截器接口
- 在value前面加上"MyProducerInterceptor:"
@Slf4j
public class MyProducerInterceptor implements ProducerInterceptor<String,String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
log.info("onSend");
return new ProducerRecord<>(record.topic(),record.partition(),record.key(),"MyProducerInterceptor:"+record.value());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
log.info("onAcknowledgement");
}
@Override
public void close() {
log.info("close");
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 在生产者配置上自定义拦截器
@Slf4j
public class MyProducer {
private static Properties props = new Properties();
static {
//指定kafka server的地址,集群配多个,中间,逗号隔开
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092,node02:9092,node03:9092");
//procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
//acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
//acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
//acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
//可以设置的值为:all, -1, 0, 1
props.put(ProducerConfig.ACKS_CONFIG, "all");
//写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
//当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
props.put(ProducerConfig.RETRIES_CONFIG, 1);
//每次批量发送消息的数量,produce积累到一定数据,一次发送
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//等待时间
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
//指定消息key和消息体的序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
}
public static void main(String[] args) {
// 2 构建拦截链
List<String> interceptors = new ArrayList<>();
interceptors.add("com.liguanqiao.study.kafka.MyProducerInterceptor");
//设置拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors);
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
simpleSend(producer, new ProducerRecord<String, String>("test-topic",
Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
/**
* 最简单的方式发送,不管消息是否正常到达
*
* @param producer
*/
private static void simpleSend(Producer<String, String> producer, ProducerRecord<String, String> record) {
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5.分区器
分区器原理
分区器案例
- 实现分区器接口
@Slf4j
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取主题的分区数
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
log.info("partition size: [{}]",numPartitions);
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 配置自定义分区器
//设置分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.liguanqiao.study.kafka.MyPartitioner");
评论区