


前言
如今我们所处的时代,是移动互联网时代,也可以说是视频时代。从快播到抖音,我们的生活,被越来越多的视频元素所影响。

而这一切,离不开视频拍摄技术的不断升级,还有视频制作产业的日益强大。

此外,也离不开通信技术的飞速进步。试想一下,如果还是当年的56K Modem拨号,或者是2G手机,你还能享受到现在动辄1080P甚至4K的视频体验吗?
除了视频拍摄工具和网络通信技术升级之外,我们能享受到视频带来的便利和乐趣,还有一个重要因素,就是视频编码技术的突飞猛进。
一、图像基础知识
1.1、像素
说视频之前,先要说说图像,图像,大家都知道,是由很多“带有颜色的点”组成的。这个点,就是“像素(pixel/px)点”。
我们所说的图像大小为1920×1080,指的就是长宽各有 1920 和 1080 的像素点,那么一张1920×1080的图片总共有的像素点为:1920×1080 = 2073600个像素点。
1.2、颜色
以前我们美术课学过,任何颜色,都可以通过红色(Red)、绿色(Green)、蓝色(Blue)按照一定比例调制出来。这三种颜色,被称为“三原色”。
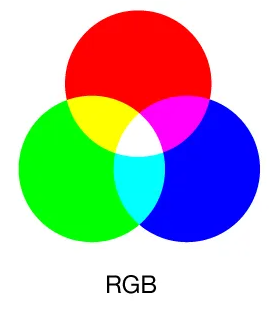
在计算机里,R、G、B也被称为“基色分量”。它们的取值,分别从0到255,一共256个等级(256是2的8次方)。所以,任何颜色,都可以用R、G、B三个值的组合表示。
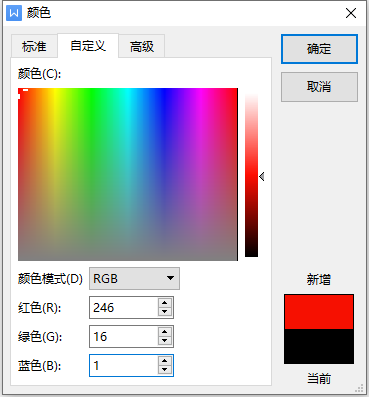
通过这种方式,一共能表达多少种颜色呢?256×256×256=16,777,216种,因此也简称为1600万色。RGB三色,每色有8bit,这种方式表达出来的颜色,也被称为24位色(占用24bit)。这个颜色范围已经超过了人眼可见的全部色彩,所以又叫真彩色。再高的话,对于我们人眼来说,已经没有意义了,完全识别不出来。

#FF0505
RGB(255,5,5)

#FF0A0A
RGB(255,10,10)
1.3、图像的大小如何计算?
图像的大小:像素数量 × 像素大小 = 图片大小,而 像素大小 和 像素深度有关系。
什么是像素深度?
色彩深度、bit到底是什么?
- 比特(bit)可以定义两个级或者两个状态:黑/白(这里就以颜色来说)
- 每增加一比特,其可定义的级或者水平,就翻一倍
比如:1bit=2levels 那么2bits=4levels 3bits=8levels…(这里不用纠结于这些理论,认识规律即可,就是2的多少次方)
那么用黑白来表示就是这样的:

1bit就只有黑和白,而2bit中间就又多了灰,以此类推,比特越高则过度越平滑。
那么一张1920 x 1280分辨率 颜色模式为8bit通道的图片 大小为:1920 x 1280 x 24 / 8 / 1024 / 1024 = 7.03125 Mb
二、视频基础知识
2.1、视频和图像的关系

视频就是图片一帧一帧连起来的产物,连起来的越快看着越流畅,用 帧率(就是每秒播放图片的数量 FPS)来衡量视频的流畅度。那么根据图片大小的算法就能算出视频的大小。
视频的大小 = 时长(秒) x 帧率(FPS)x 图片大小;
几个概念
- 帧(Frame):就是一张静止的画面, 是视频的最小单位。
- 帧速率(FPS):每秒播放图片的数量。
- 码率(Bit Rate):视频文件在单位时间内使用的数据流量,决定视频的质量和大小,单位是 kb/s 或者 Mb/s。
那么1920×1280分辨率, 30FPS,时长 1 秒的视频的大小就是:1 x 30 x 7.03125 = 210.9375 Mb ,以一部 90 分钟电影需要:210.9 x 60 x 90 / 1024 = 1112.1679 G,不禁产生疑问,为啥我下载的大片才 1G 多?莫慌,视频要是这么简单,那我们就太天真了,所以就有了下文 「视频编码」 。
三、视频编码
3.1、什么是编码?
我们先来看看,视频从录制到播放的整个过程,如下:
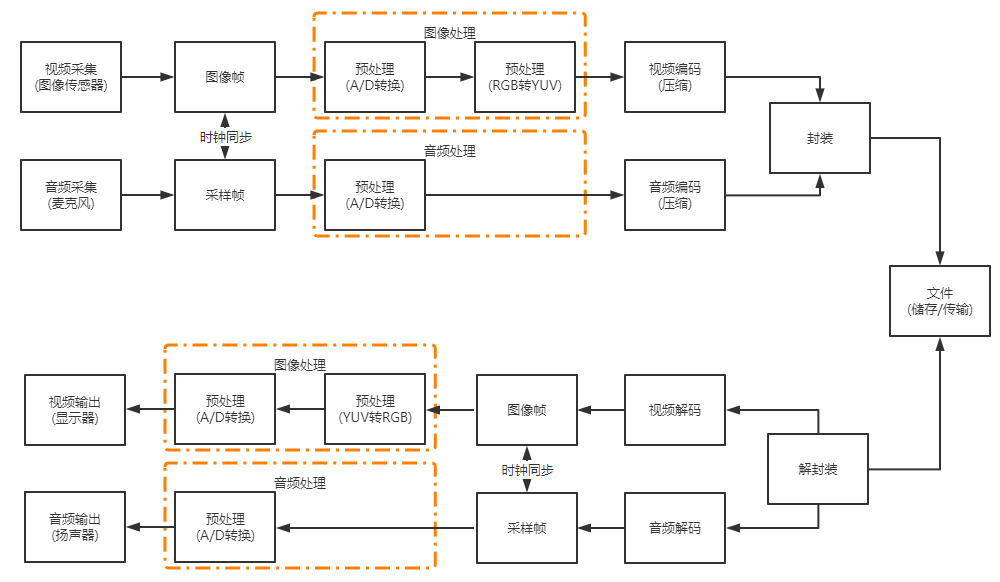
- 视频采集:通常我们会使用摄像机、摄像头进行视频采集。
- A/D转换:采集了视频数据之后,就要进行模数转换,将模拟信号变成数字信号。
- YUV转换:将RGB信号变成YUV信号。
- 编码:将信息从一种形式(格式),转换成另一种形式(格式)。实现压缩,将视频数据中的冗余信息去除。

- 封装:将已经编码压缩好的视频轨和音频轨按照一定的格式放到一个文件中。
- 解封装:将输入的封装格式的数据,分离为音频流压缩编码数据和视频流压缩编码数据,即:分离信道。
- 解码:将视频/音频压缩编码数据,解码成为非压缩的视频/音频原始数据。通过解码,压缩编码的视频数据输出成为非压缩的颜色数据,例如YUV420P,RGB等等;压缩编码的音频数据输出成为非压缩的音频抽样数据,例如PCM数据。
- 音视频同步:根据解封装模块处理过程中获取到的参数信息,同步解码出来的视频和音频数据,并将视频音频数据送至系统的显卡和声卡播放出来。
编码的终极目的,说白了,就是为了压缩。各种五花八门的视频编码方式,都是为了让视频变得体积更小,有利于存储和传输。
3.2、什么A/D转换?
自然界中的绝大部分信号是模拟信号,如语音和音频信号、雷达和声纳数据、地震和生物信号等。为了对这些模拟信号进行数字化的处理,首先是要将模拟信号转换为数字信号。在信号处理中,这个转换的过程称为“模-数”变换(Analog-Digital,A/D)。实现A/D变换的器件叫做“模-数”变换器(Analog-Digital Converter, ADC)。A/D变换的实现过程如图所示。由图可以看出,实现A/D变换主要包括三个步骤:
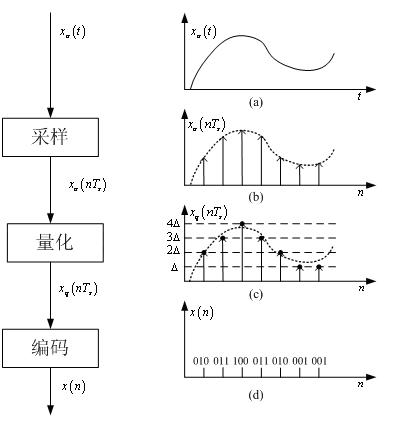
- 采样:模拟信号首先被等间隔地取样,这时信号在时间上就不再连续了,但在幅度上还是连续的。经过采样处理之后,模拟信号变成了离散时间信号。
- 量化:每个信号采样的幅度以某个最小数量单位△的整数倍来度量。这时信号不仅在时间上不再连续,在幅度上也不连续了。经过量化处理之后,离散时间信号变成了数字信号。
- 编码:将数字信号编码成B位长度的二进制字。虽然在量化之后信号已经变成了数字信号,但二进制字的表示方法有很多。ADC还要根据精度、动态范围及实现成本等多个角度选择所需的二进制编码方式。
经过编码处理之后得到的信号才是我们通常所说的比特流。对这个比特流的处理才是通常所说的数字信号处理。在数字信号处理理论中,经过采样处理得到离散信号是最为关键的一步。只有在考虑到具体实现的时候,量化和编码的问题才必须要考虑。这也是数字信号处理有时也称为离散时间信号处理的原因所在。
3.3、什么是YUV信号?
简单来说,YUV就是另外一种颜色数字化表示方式。视频通信系统之所以要采用YUV,而不是RGB,主要是因为RGB信号不利于压缩。在YUV这种方式里面,加入了亮度这一概念。在最近十几年中,视频工程师发现,眼睛对于亮和暗的分辨要比对颜色的分辨更精细一些,也就是说,人眼对色度的敏感程度要低于对亮度的敏感程度。
所以,工程师认为,在我们的视频存储中,没有必要存储全部颜色信号。我们可以把更多带宽留给黑—白信号(被称作“亮度”),将稍少的带宽留给彩色信号(被称作“色度”)。于是,就有了YUV。
大家偶尔会见到的Y'CbCr,也称为YUV,是YUV的压缩版本,不同之处在于Y'CbCr用于数字图像领域,YUV用于模拟信号领域,MPEG、DVD、摄像机中常说的YUV其实就是Y'CbCr。

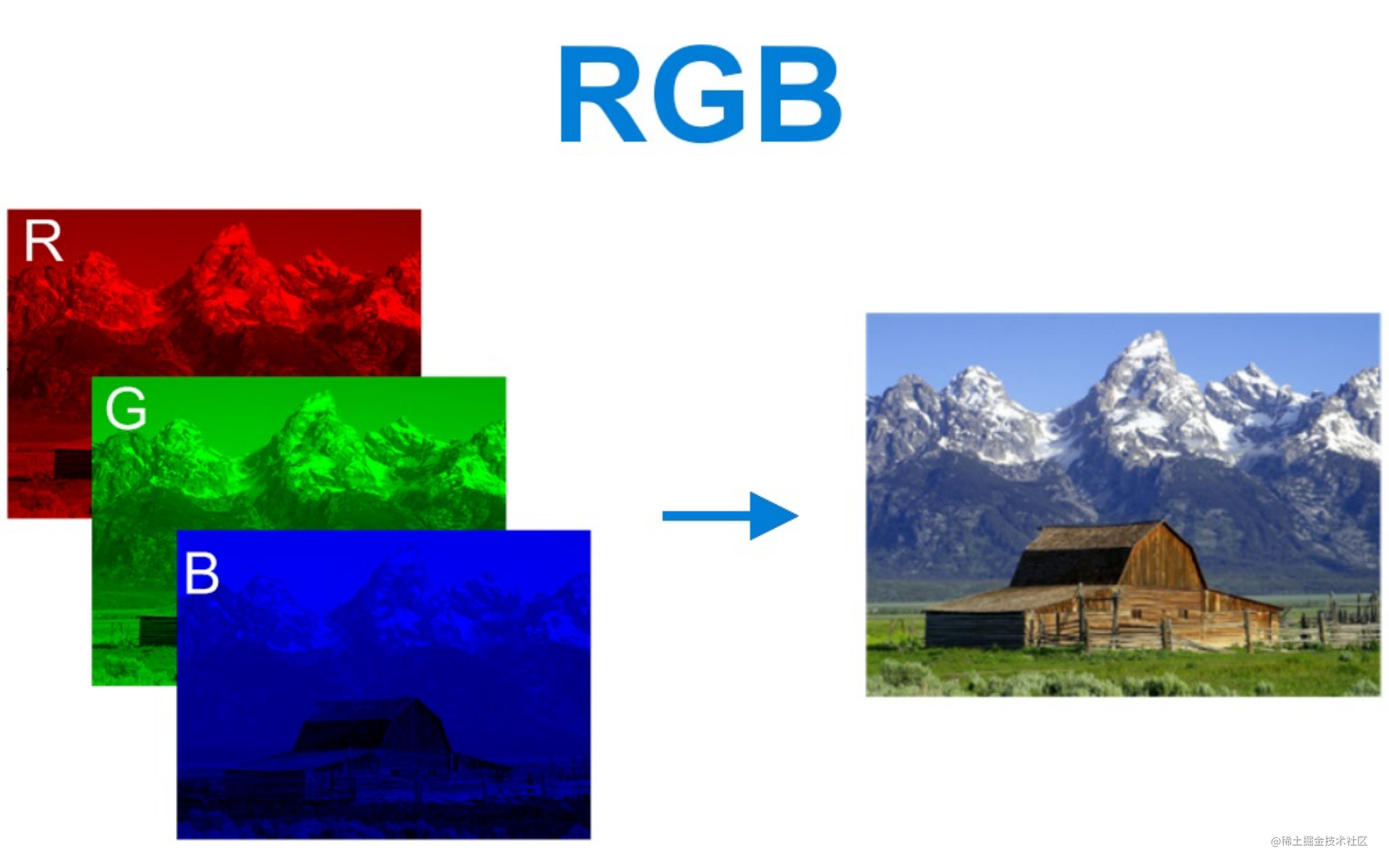
RGB如何形成图像
YUV如何形成图像
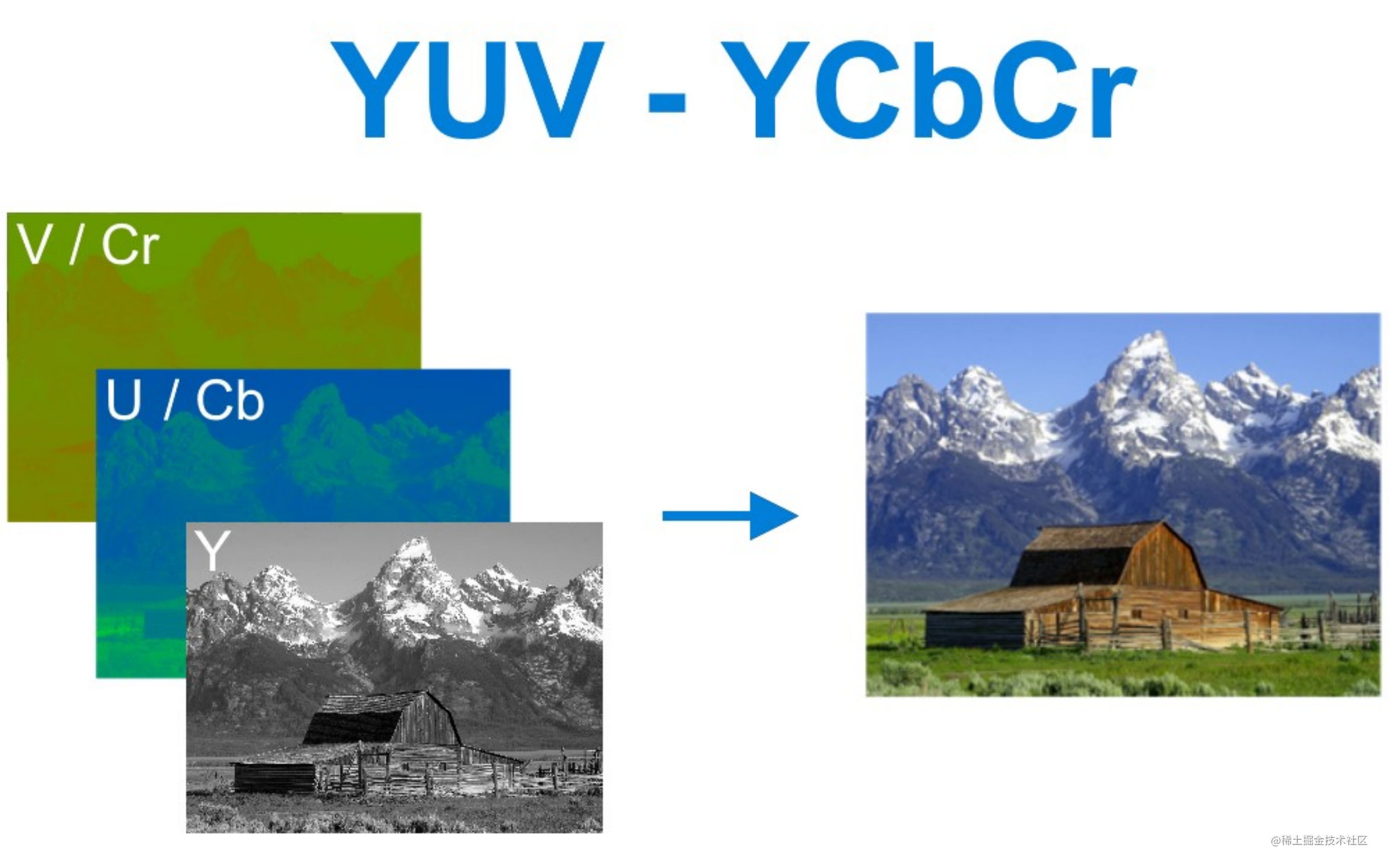
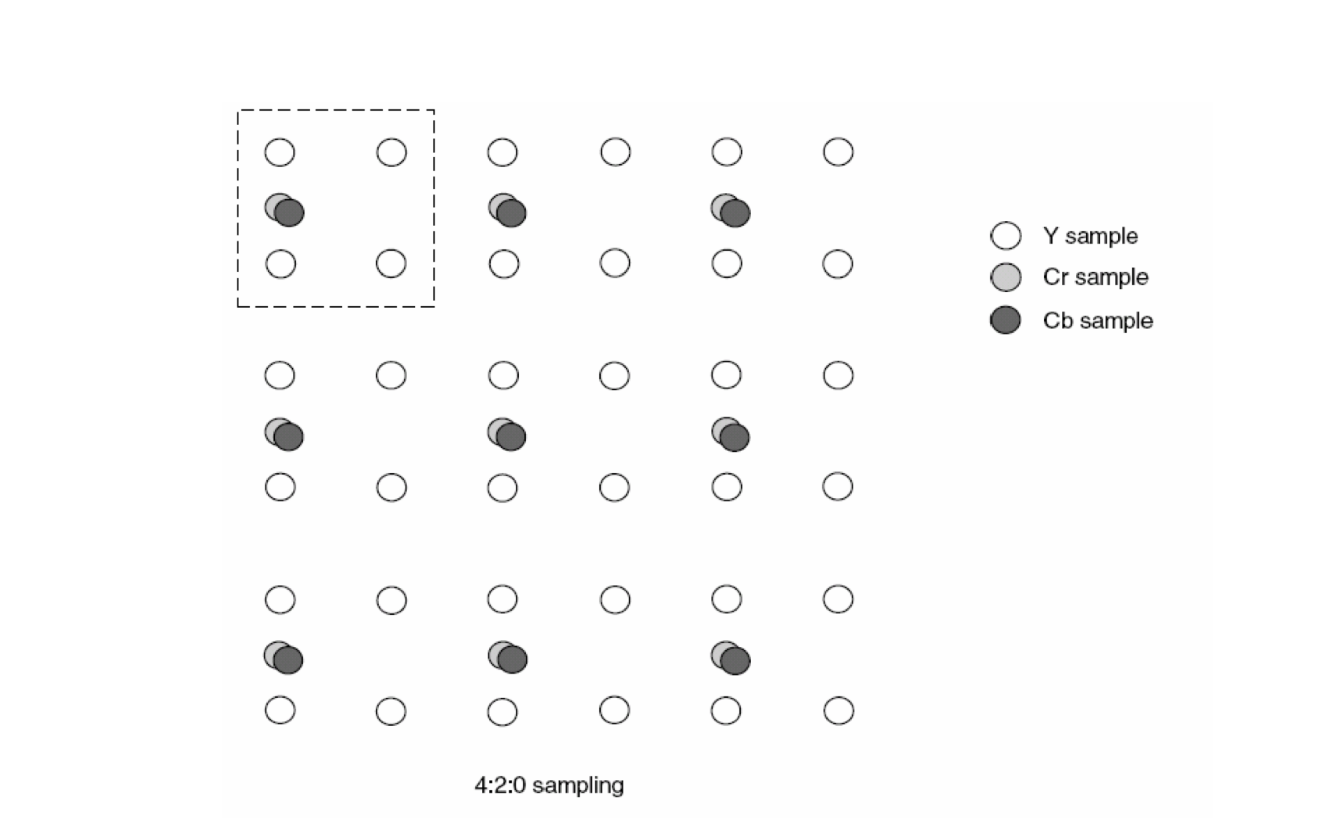
YUV常用采样方式
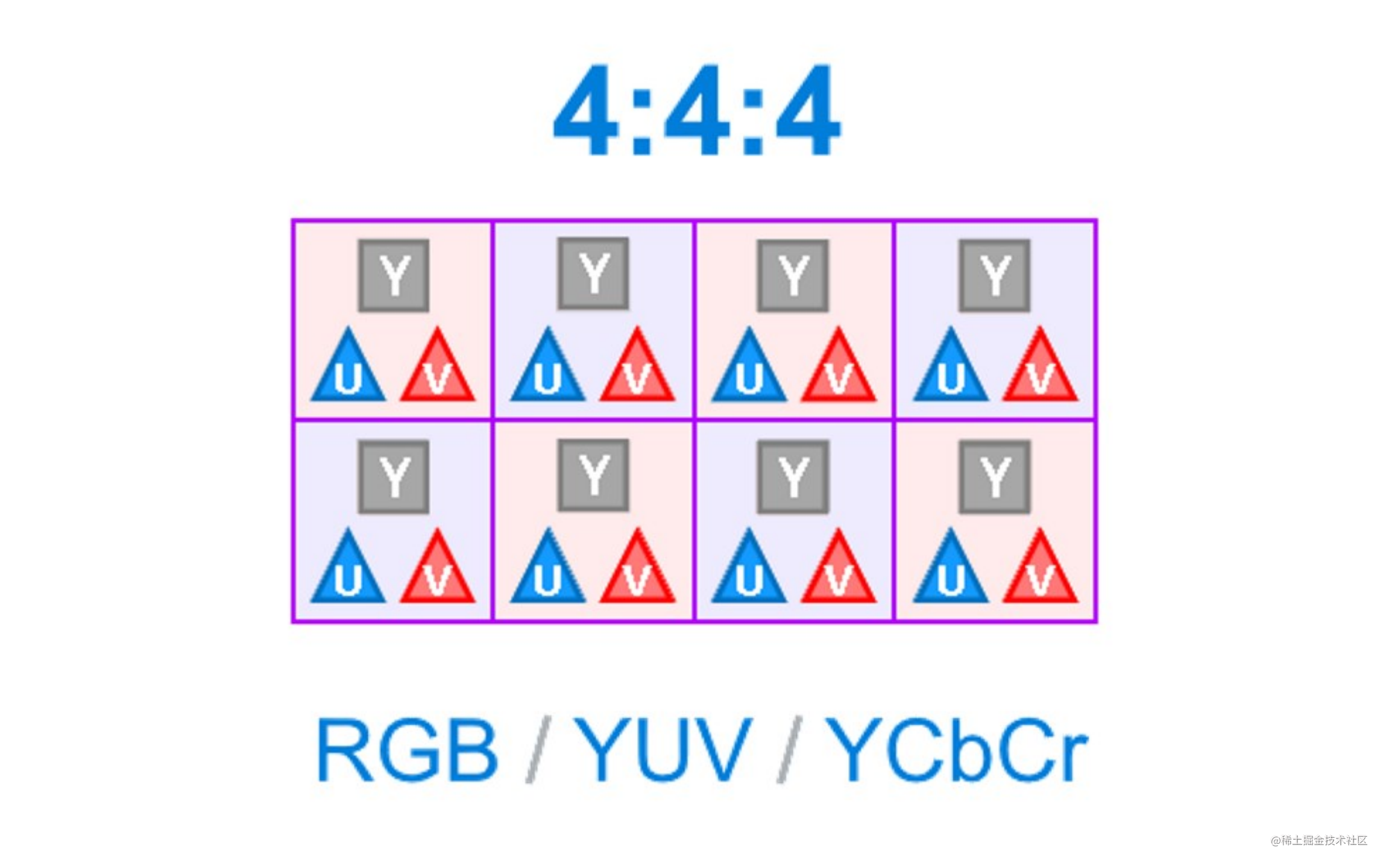
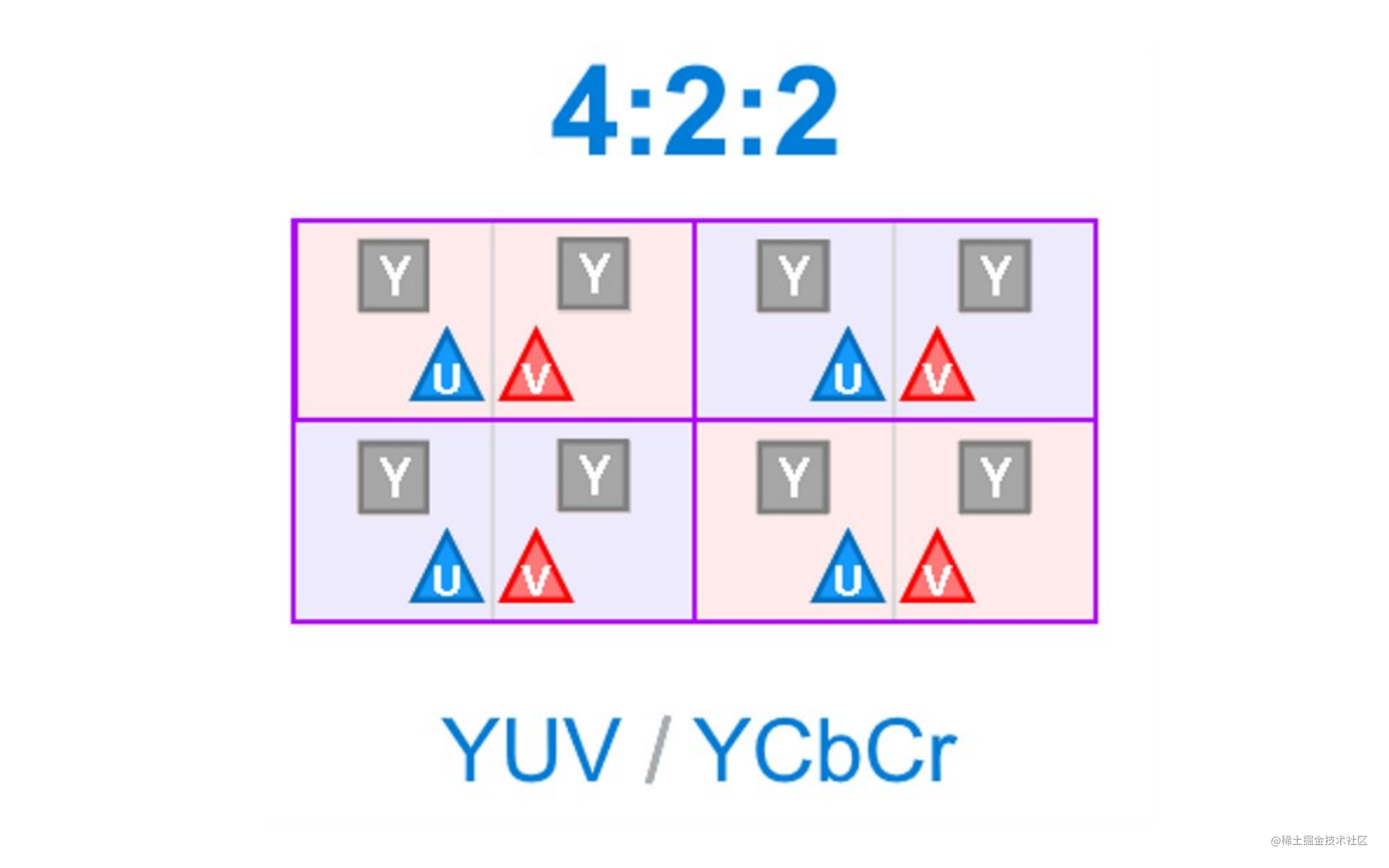
主流的YUV采样方式有如下三种:
-
YUV444
-
YUV422
-
YUV420
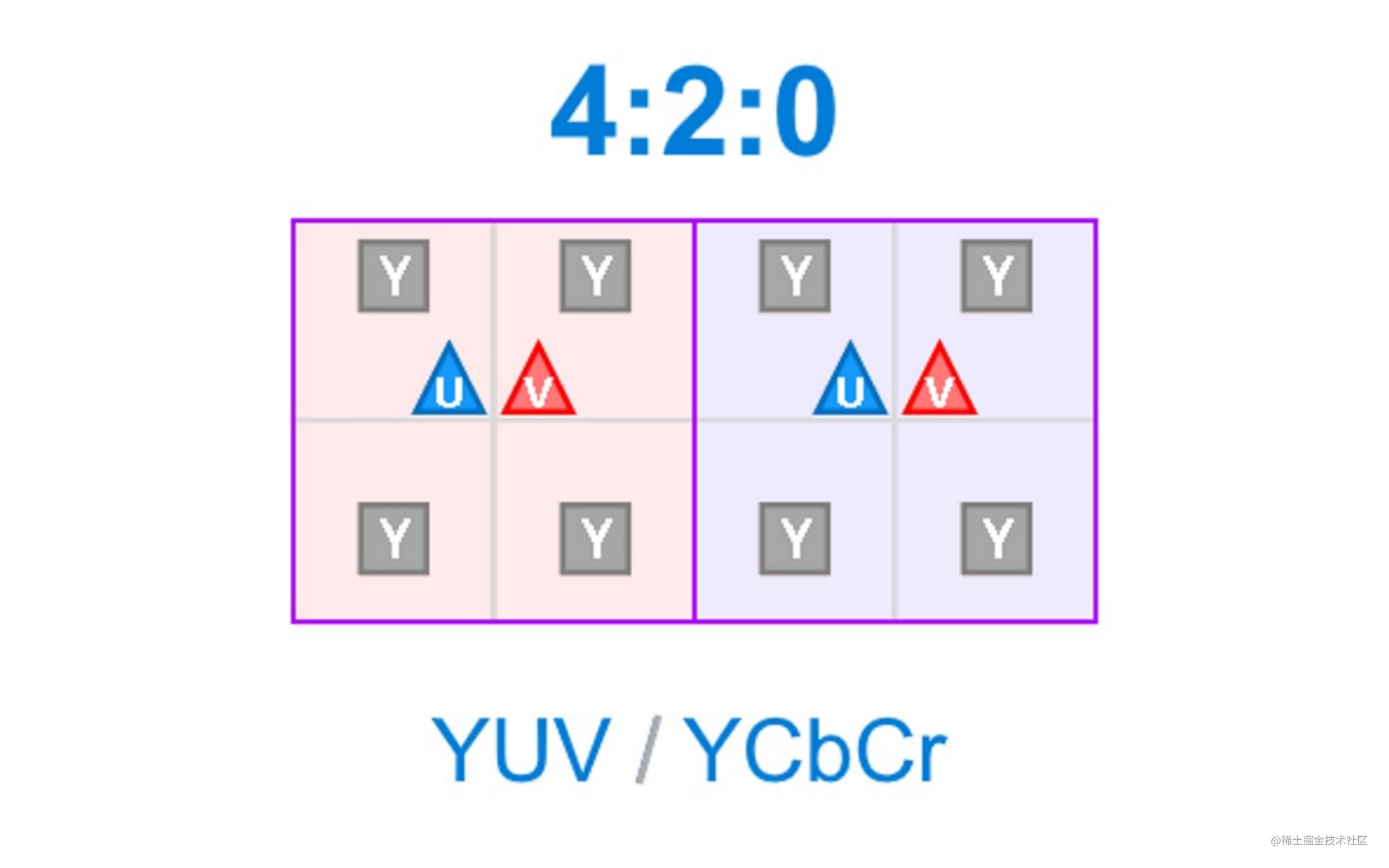
通常用的是YUV4:2:0的采样方式,能获得1/2的压缩率。
3.4、编码的实现原理
前面我们说了,编码就是为了压缩。要实现压缩,就要设计各种算法,将视频数据中的冗余信息去除。
通常来说,视频里面的冗余信息包括:
- 空间冗余:图像相邻像素之间有较强的相关性,比如一帧图像划分成多个 16x16 的块之后,相邻的块很多时候都有比较明显的相似性。
- 时间冗余:视频序列的相邻前后帧图像之间内容相似,比如帧率为 25fps 的视频中前后两帧图像相差只有 40ms,前后两张图像的变化较小,相似性很高。
- 视觉冗余:我们的眼睛对某些细节不敏感,对图像中高频信息的敏感度小于低频信息的。可以去除图像中的一些高频信息,人眼看起来跟不去除高频信息差别不大(有损压缩)。
- 编码冗余(信息熵冗余):一幅图像中不同像素出现的概率是不同的。对出现次数比较多的像素,用少的位数来编码。对出现次数比较少的像素,用多的位数来编码,能够减少编码的大小。比如哈夫曼编码。
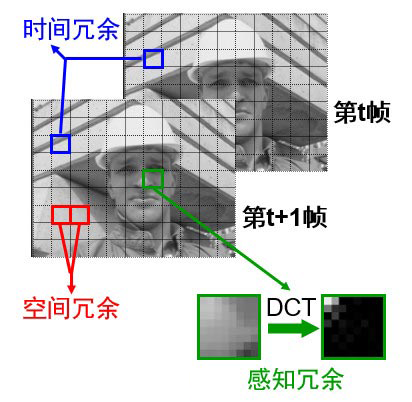
3.5、空间冗余/帧内预测
前面我们了解到一张图片是由n个像素组成,当你面对一张图片你想一想,如果是你,你会如何进行压缩呢?

我觉得,首先你想到的,应该是找规律。是的,寻找像素之间的相关性;
举个例子:如果一幅图(1920×1080分辨率),全是红色的,我有没有必要说2073600次[255,0,0]?我只要说一次[255,0,0],然后再说2073599次“同上”

编码图像
编码图像通常将当前帧的图片进行图像切割为不同的宏块,对它们进行计算。一个宏块一般为16像素×16像素。

▲将图片切割为宏块
一个宏块由一个 16×16 亮度像素(Y)、一个 8×8 (Cb/U)以及一个 8×8 (Cr/V) 彩色像素块组成,即常见的420采样格式
宏块也有多种类型,每种类型都带不同的宏块大小、帧内预测模式、帧间预测模式等信息。
16 × 16亮度块的4种预测模式
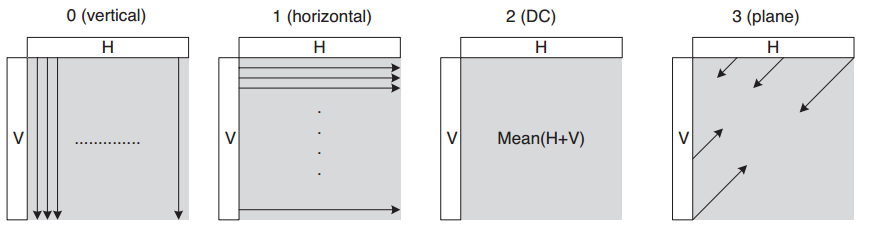
4种预测模式说明如下
- Mode0 (vertical): 由上方的样本(H)垂直推算
- Mode1 (horizontal) 由左侧的样本(V)水平推算
- Mode2 (DC): 上方的样本(H)和左侧的样本(V)的平均值
- Mode3 (Plane): 根据上方的样本(H)和左边的样本(V)通过一个plane函数得出,在亮度平滑变化的区域工作得很好。

4 × 4亮度块的9种预测模式
4x4预测块的像素使用小写字母a-p标示,预测块左侧和上方的参考像素使用大写字母A-M标示:
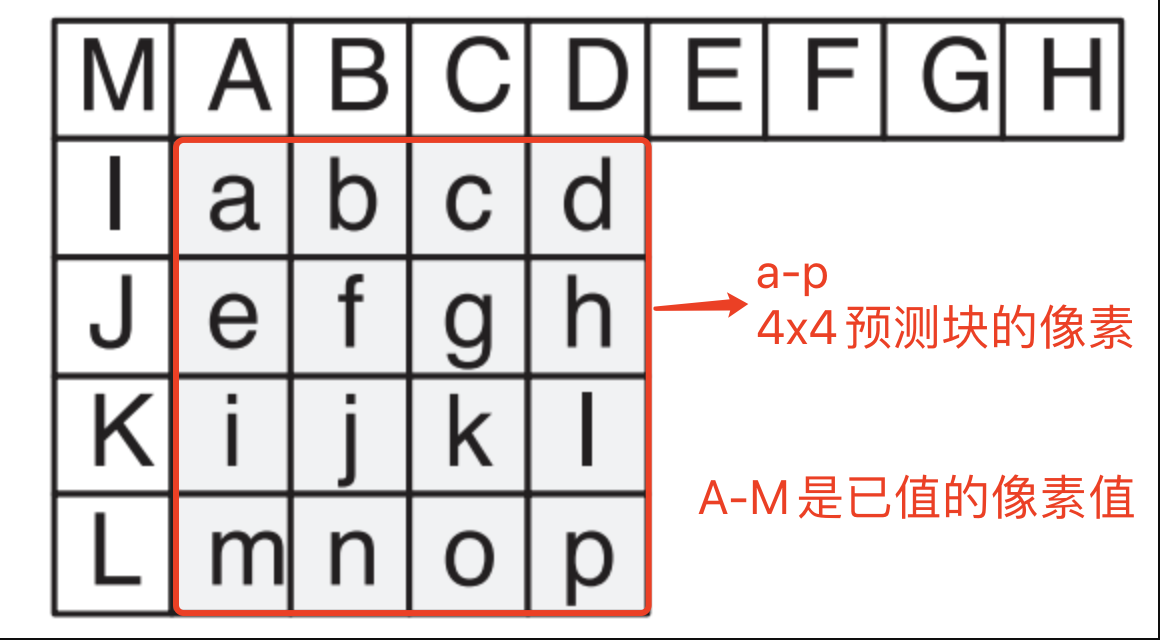
4x4亮度块有9中预测模式,分别如下
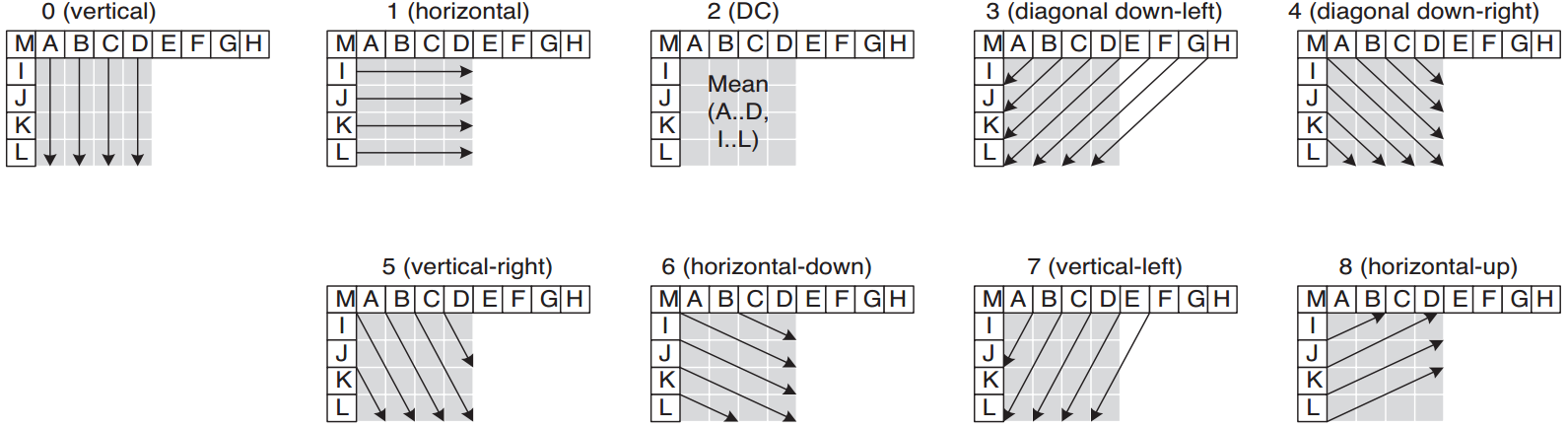
其中预测模式2 的所有样本预测值都等于A-D以及I-L的平均值。
其他8中模式的8歌方向的预测示意图如下所示:
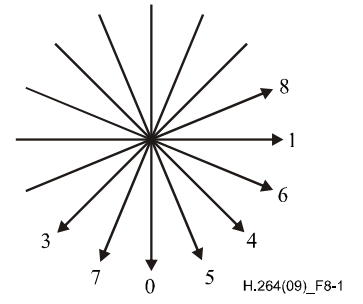
9种预测模式说明如下:
- Mode0 (Vertical): 由上方的A、B、C、D进行垂直推算
- Mode1 (Horizontal) : 由左侧的I、J、K、L进行水平推算
- Mode2 (DC) : P中的所有样本预测值都等于AD及IL的平均值
- Mode3 (Diagonal Down-Left): 由45度角方向的左下和右上的样本内插得出
- Mode4 (Diagonal Down-Right): 以45度角往右下的方向进行推算
- Mode5 (Vertical-Right) : 以垂直向下方向右偏大约26.6度角(即width/height = 1/2)的方向推行推算。
- Mode6 (Horizontal-Down): 以水平向右方向下偏大约26.6度角的方向进行推算。
- Mode7 (Vertical-Left): 以垂直向下方向左偏大约26.6度角的方向推行推算。
- Mode8 (Horizontal-Up): 以水平向右方向上偏大约26.6度角的方向进行推算。

3.6、时间冗余/帧间预测
什么是GOP?
如果一段1分钟的视频,有十几秒画面是不动的,或者,有80%的图像面积,整个过程都是不变(不动)的。那么,是不是这块存储开销,就可以节约掉了?

我们知道视频是由不同的帧画面连续播放形成的。
这些帧,主要分为三类,分别是:
- I帧:是自带全部信息的独立帧,是最完整的画面(占用的空间最大),无需参考其它图像便可独立进行解码。视频序列中的第一个帧,始终都是I帧。
- P帧:“帧间预测编码帧”,需要参考前面的I帧和/或P帧的不同部分,才能进行编码。P帧对前面的P和I参考帧有依赖性。但是,P帧压缩率比较高,占用的空间较小。
- B帧:“双向预测编码帧”,以前帧后帧作为参考帧。不仅参考前面,还参考后面的帧,所以,它的压缩率最高,可以达到200:1。不过,因为依赖后面的帧,所以不适合实时传输(例如视频会议)。
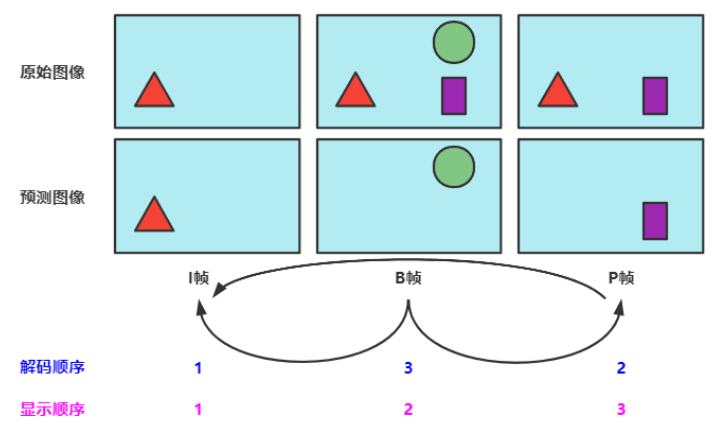
一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。
在视频编码序列中,GOP即Group of picture(图像组),指两个IDR帧之间的距离。
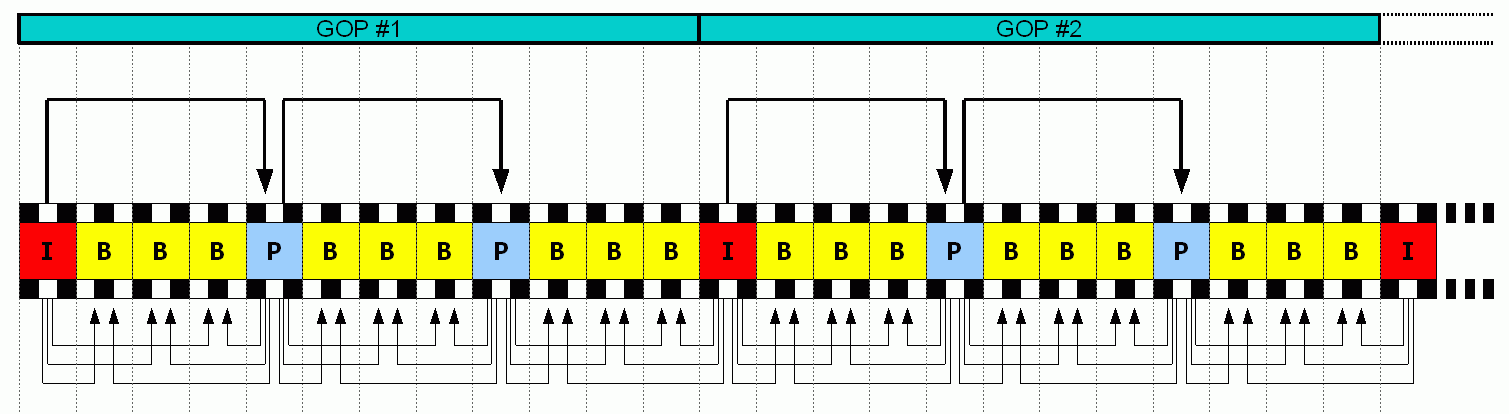
GOP长度越大,视频压缩效率越高,但视频质量和视频流恢复能力也越差,反之亦
然。
直播,如果是一秒25帧,一般gop设置为25, 50(一般是帧率的倍数).
3.7、DCT、量化、熵编码
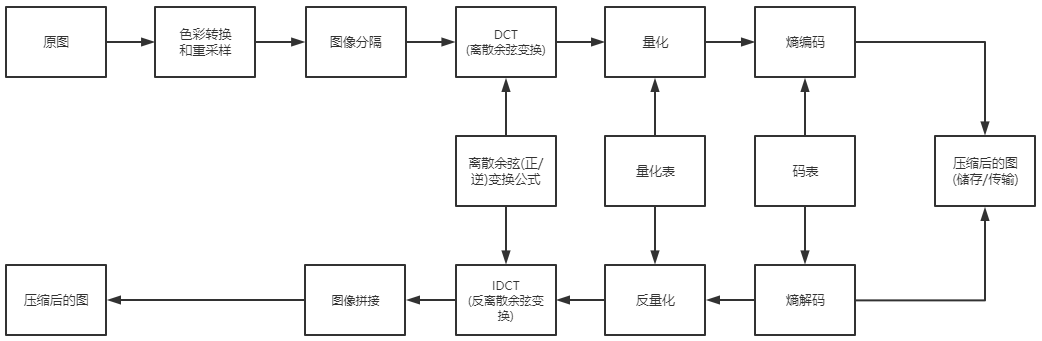
▲ JPEG压缩/解压缩的流程图
颜色转换和重采样
参考 什么是YUV信号
图像分隔
如下图所示。比如一个160x160大小的原始图像,就可以分成20x20个8x8图像块。
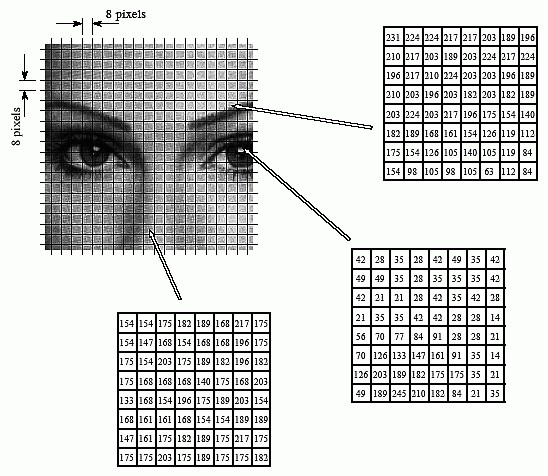
视频帧内预测里的宏块分割就是图片分隔
DCT与IDCT
一个是正变换,一个是逆变换。反正都可以称为离散余弦变换。
正变换公式
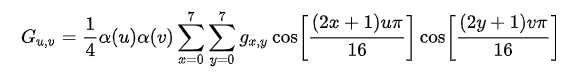
逆变换公式
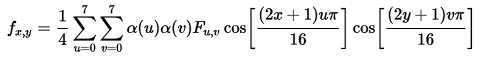
其中:
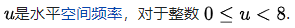
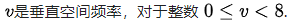



不要把上式看的有多难,也不要被“离散余弦变换”这个词给吓到,其实他没什么(如果你非要去追究,那就打开“信号与系统”的书复习一下吧,我拦不住你哈),上式其实就是一个运算公式而已。
输入就是8x8的数据矩阵,经过计算,输出还是一个8x8的数据矩阵。
量化与反量化
定义:将DCT变换后的临时结果,除以各自量化步长并四舍五入后取整,得到量化系数。
人眼善于在相对较大的区域内看到微小的亮度差异,但不太擅长区分高频亮度变化的确切强度。这允许大大减少高频分量中的信息量。只需将频域中的每个分量除以该分量的常数,然后四舍五入到最接近的整数即可。
在术语里,左上方称为低频数据,右下方称为高频数据。
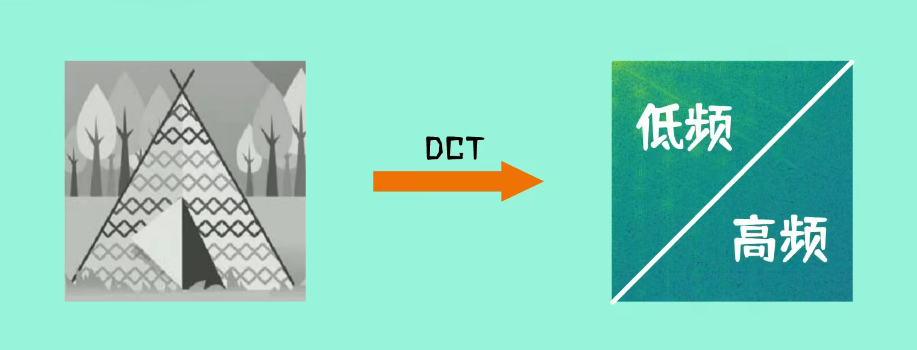
JPEG系统分别规定了亮度分量和色度分量的量化表,色度分量相应的量化步长比亮度分量大。
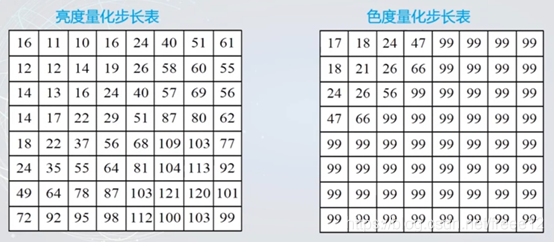
▲ JPEG格式标准量化表
熵编码
熵编码是一种特殊形式的无损数据压缩。它涉及以“之字形”顺序排列图像组件,采用运行长度编码(RLE)算法将相似的频率组合在一起,插入长度编码零,然后使用霍夫曼编码剩余的内容。
JPEG提供了一张标准的码表用于对这些数字编码:

应用举例
编码
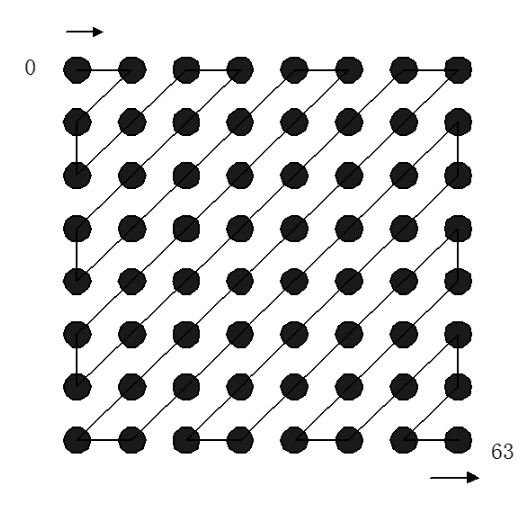
例如,一个这样的 8×8 8 位子图像可能是:
由于一个字节是0~255,为了减小绝对值波动,先把数值移位一下,变成-128~127。
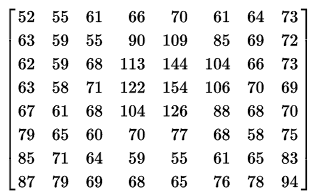
接着,根据DCT变换公式,各种计算,获得临时结果。
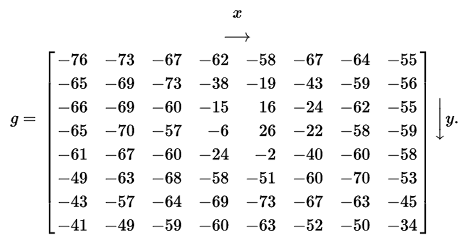
根据亮度量化表量化后得到的量化系数矩阵
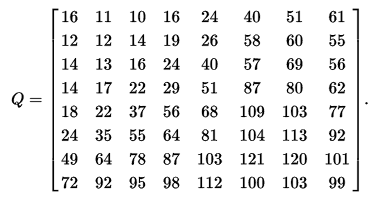
获得量化结果:

解码
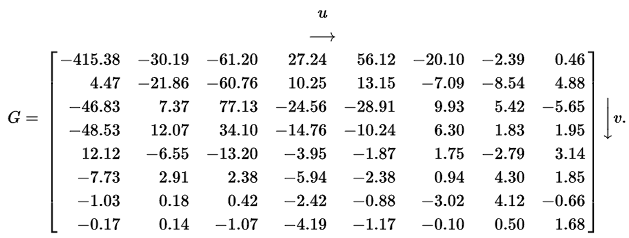
先熵解码恢复为

然后,根据亮度量化表进行反量化
获得反量化后的结果

再根据反离散余弦变换的公式进行计算,结果为

再右移127,恢复原始。
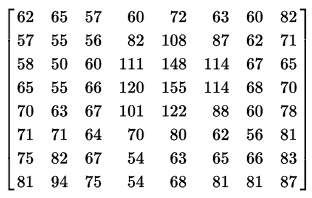
和原始图像的数据相比,基本是一样的,或者近似的!

相关文章:https://en.wikipedia.org/wiki/JPEG#Discrete_cosine_transform
四、视频编码的国际标准
4.1、视频编码格式的标准化
任何技术,都有标准。自从有视频编码以来,就诞生过很多的视频编码标准。
为何需要标准化?:主要目的是可以达到不同公司不同产品之间的互联互通。比如由某一厂家编码器得到的视频码流可以被其它不同的厂家生产的解码器播放。
提到视频编码标准,先介绍几个制定标准的组织。
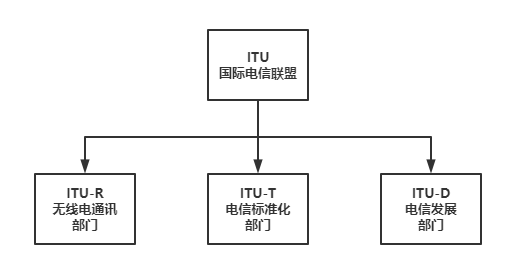
首先,就是大名鼎鼎的ITU(国际电信联盟)。

ITU是联合国下属的一个专门机构,其总部在瑞士的日内瓦。
ITU下属有三个部门:
- 1)分别是ITU-R(前身是国际无线电咨询委员会CCIR);
- 2)ITU-T(前身是国际电报电话咨询委员会CCITT);
- 3)ITU-D。
除了ITU之外,另外两个和视频编码关系密切的组织,是ISO/IEC。


ISO大家都知道,就是推出ISO9001质量认证的那个“国际标准化组织”。IEC,是“国际电工委员会”。1988年,ISO和IEC联合成立了一个专家组,负责开发电视图像数据和声音数据的编码、解码和它们的同步等标准。这个专家组,就是大名鼎鼎的MPEG,Moving Picture Expert Group(动态图像专家组)。
三十多年以来,世界上主流的视频编码标准,基本上都是它们提出来的:
- 1)ITU提出了H.261、H.262、H.263、H.263+、H.263++,这些统称为H.26X系列,主要应用于实时视频通信领域,如会议电视、可视电话等;
- 2)ISO/IEC提出了MPEG1、MPEG2、MPEG4、MPEG7、MPEG21,统称为MPEG系列。
ITU和ISO/IEC一开始是各自捣鼓,后来,两边成立了一个联合小组,名叫JVT(Joint Video Team,视频联合工作组)。
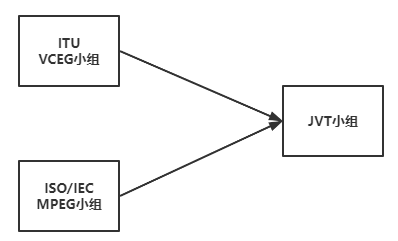
JVT致力于新一代视频编码标准的制定,后来推出了包括H.264在内的一系列标准。
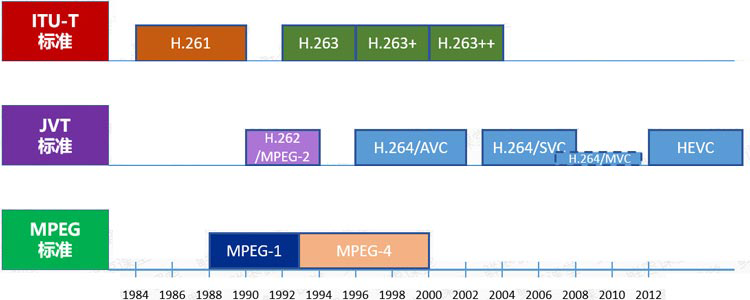
▲ 视频编码标准的发展关系
大家特别注意一下上图里面的HEVC,也就是现在风头正盛的H.265。

作为一种新编码标准,相比H.264有极大的性能提升,目前已经成为最新视频编码系统的标配。
4.2、视频数据的封装
对于任何一部视频来说,只有图像,没有声音,肯定是不行的。所以,视频编码后,加上音频编码,要一起进行封装。
封装:就是封装格式,简单来说,就是将已经编码压缩好的视频轨和音频轨按照一定的格式放到一个文件中。再通俗点,视频轨相当于饭,而音频轨相当于菜,封装格式就是一个饭盒,用来盛放饭菜的容器。
目前主要的视频容器有如下:MPG、VOB、MP4、3GP、ASF、RMVB、WMV、MOV、Divx、MKV、FLV、TS/PS等。
封装之后的视频,就可以传输了,你也可以通过视频播放器进行解码观看。
评论区